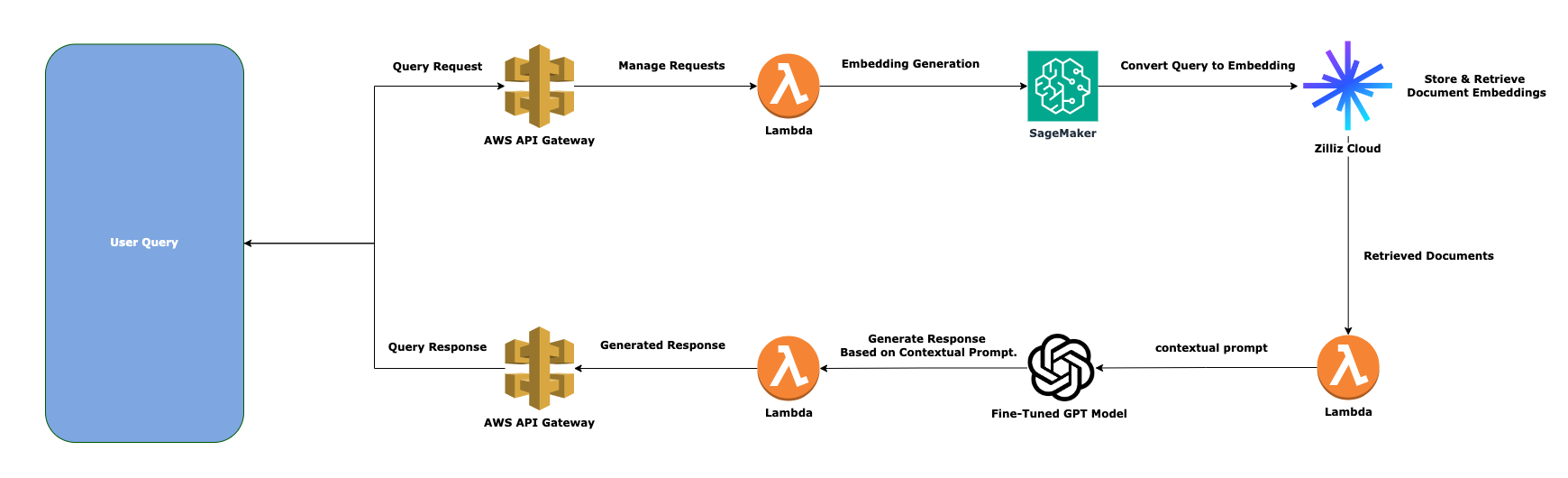
In today’s data-rich world, businesses face the challenge of delivering fast, accurate, and context-driven responses, especially in customer support, knowledge management, and research. An Enterprise RAG System offers scalable solutions for real-time, context-driven AI. Retrieval-Augmented Generation (RAG) is an advanced AI solution that combines real-time data retrieval with generative language models, ensuring context-aware and up-to-date responses. This guide explores how to build an enterprise-grade RAG system using AWS SageMaker, Zilliz Cloud (a vector database powered by Milvus), and GPT-based models. We’ll cover its architecture, implementation steps, real-world applications, and how it differs from traditional machine learning (ML)-only systems. This setup can be transformative for organizations looking to implement state-of-the-art AI solutions, making RAG an ideal choice for ThamesTech AI’s clients.
What is Retrieval-Augmented Generation (RAG)?
RAG integrates a retrieval layer with a generative model. Here’s a simplified breakdown:
- Retrieval Layer: Dynamically retrieves relevant, up-to-date information from a knowledge base or vector database based on user queries.
- Generative Layer: Uses a fine-tuned large language model, like GPT, to generate coherent responses using the retrieved information, ensuring answers are grounded in current, context-rich data.
Why RAG is Ideal for Enterprise Applications
RAG provides distinct advantages that make it particularly suited for industries like customer support, healthcare, finance, and legal research:
- Real-Time Data Access: By pulling relevant data instantly from a vector database, RAG ensures that responses are up-to-date.
- Cost Efficiency: The separation of retrieval and generation minimizes frequent model retraining, saving costs and improving operational efficiency.
- Enhanced Accuracy: With retrieval-driven context, RAG reduces the chances of “hallucinations” (where the model generates plausible but incorrect answers), delivering more accurate and reliable outputs.
Core Components of a Enterprise RAG System on AWS and Zilliz Cloud
Setting up a robust Enterprise RAG system involves several key components, each enhancing the system’s efficiency, scalability, and accuracy.
-
Data Storage and Management:
- Amazon S3: Securely stores large datasets (e.g., policy documents, research articles) that can be easily accessed for embedding and retrieval.
- DynamoDB: Manages metadata and supports structured lookups, optimizing retrieval of information for efficient system performance.
-
Embedding Generation:
- Amazon SageMaker: Converts text documents into embeddings (vector representations) using pre-trained models like BERT, which capture semantic meaning for accurate similarity searches.
- Fine-Tuned GPT Models: GPT models are fine-tuned on specific domain data, ensuring responses align with industry-specific terminology and context.
-
Vector Database for Efficient Retrieval:
- Zilliz Cloud (Milvus): Zilliz Cloud stores high-dimensional embeddings and enables fast, accurate retrieval using techniques like Hierarchical Navigable Small World (HNSW) indexing. Optimized for handling large-scale similarity searches, it’s a robust choice for enterprise applications.
-
Generative Model for Response Creation:
- GPT Model (Fine-Tuned): A fine-tuned GPT model interprets prompts and generates coherent responses using the retrieved information, producing contextually accurate outputs.
-
API Management:
- AWS API Gateway and Lambda: AWS API Gateway manages incoming requests, while Lambda orchestrates retrieval and generation processes. This serverless architecture is efficient and scales effortlessly based on demand.
Implementing a Enterprise RAG System: A Step-by-Step Guide
Step 1: Data Preparation and Embedding Generation
To achieve high-quality retrieval, documents need to be properly processed and embedded.
-
Chunking and Preprocessing: Split documents into smaller sections (200–300 tokens each) with overlapping text for greater relevance.
-
Embedding Creation with SageMaker: Use SageMaker to convert these document chunks into embeddings using a pre-trained model like BERT. These embeddings capture each chunk’s semantic meaning for more accurate similarity search.
import boto3 import sagemaker from sagemaker.huggingface import HuggingFaceModel # Configure SageMaker for embedding generation huggingface_model = HuggingFaceModel( model_data="s3://path-to-pretrained-bert", role=sagemaker.get_execution_role(), transformers_version="4.17", pytorch_version="1.10", py_version="py38" ) # Generate embeddings and deploy as a SageMaker endpoint predictor = huggingface_model.deploy(initial_instance_count=1, instance_type="ml.m5.large") embeddings = predictor.predict({"inputs": ["Sample document text for embedding"]}) predictor.delete_endpoint()
Step 2: Storing and Retrieving Embeddings in Zilliz Cloud
Zilliz Cloud, powered by Milvus, is a high-speed vector database optimized for large-scale similarity search, which is essential for dynamic data environments.
-
Embedding Storage in Zilliz Cloud: Upload embeddings to Zilliz Cloud for real-time indexing, enabling high-speed similarity search.
-
Query Processing: Convert user queries into embeddings and retrieve relevant document sections based on similarity search in Zilliz Cloud, forming the context for the generative model’s response
from pymilvus import connections, CollectionSchema, FieldSchema, DataType, Collection # Connect to Zilliz Cloud and define schema connections.connect(alias="default", uri="your-zilliz-cloud-uri", token="your-api-token") schema = CollectionSchema([ FieldSchema(name="id", dtype=DataType.INT64, is_primary=True), FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768) ]) collection = Collection("document_embeddings", schema=schema) collection.insert([doc_ids, document_embeddings])
Step 3: Constructing the Contextual Prompt
-
Embedding Query: Convert the user’s question into an embedding. Zilliz Cloud retrieves relevant document sections based on semantic similarity.
-
Prompt Creation: Construct a prompt combining the retrieved document content with the user’s question, providing GPT with a context-rich input for more relevant responses.
Based on the following documents, answer the user’s question. Document 1: [Relevant content from document 1] Document 2: [Relevant content from document 2] User Question: What are the terms for policy renewal?
Step 4: Response Generation Using Fine-Tuned ChatGPT
With the contextual prompt ready, send it to a fine-tuned GPT model for generating a response.
import openai openai.api_key = "your-openai-api-key" response = openai.Completion.create( model="ft-your-finetuned-gpt-model-id", prompt=constructed_prompt, max_tokens=200 ) print(response.choices[0].text.strip())
RAG vs. Traditional ML-Only Systems: Why RAG is Superior
-
Dynamic Data Access: Traditional ML systems are trained on static data and require frequent retraining to stay current. RAG’s retrieval layer accesses external data in real-time, reducing the need for costly model retraining while maintaining up-to-date answers.
-
Reduced Hallucination and Improved Accuracy: By grounding responses in retrieved content, RAG minimizes the risk of “hallucinations” (where models produce plausible but incorrect information), a common challenge in ML-only generative setups.
-
Scalability and Cost Efficiency: RAG systems separate data retrieval from generation, allowing vector databases to manage dynamic information without increasing compute requirements for the generative model. This makes it more scalable and cost-effective for handling large volumes of data.
-
Enhanced Adaptability: RAG’s modular architecture means it can quickly adapt to new data by updating embeddings without retraining the main model, a major advantage for industries with rapidly changing information, like finance or healthcare.
Real-World Applications of Enterprise RAG Systems
-
Customer Support Automation: RAG-powered chatbots dynamically retrieve the latest troubleshooting guides, product manuals, and policy information, offering accurate, context-specific answers in real time, reducing support costs and improving customer satisfaction.
-
Legal and Compliance Research: Legal teams use RAG to retrieve relevant case law, statutes, or compliance documents on demand, enabling quick, contextually appropriate responses without extensive manual research.
-
Healthcare Decision Support: Healthcare providers leverage RAG to access the latest medical guidelines, research articles, or treatment protocols, providing clinicians with accurate and evidence-based recommendations.
Conclusion
Using Amazon SageMaker for embedding generation, Zilliz Cloud for vector storage, and fine-tuned ChatGPT for contextual response generation, Enterprise RAG systems offer a powerful, scalable, and adaptable solution for enterprise applications. RAG not only improves accuracy and relevance but also reduces operational costs by eliminating frequent model retraining. This architecture supports rapid adaptation to new information, making it ideal for fast-evolving, dynamic, and information-intensive industries such as healthcare, finance, and legal services. This system’s design ensures that organizations can deliver high-quality, contextually accurate responses, which are essential for making informed, timely decisions.
By decoupling data retrieval from model generation, RAG systems enhance accuracy, cost-effectiveness, and scalability, providing significant advantages over traditional ML-only approaches. Enterprises looking to build responsive, context-aware AI applications will find RAG aninvaluable architecture for meeting modern information demands.
References
- OpenAI Documentation on Fine-Tuning and Prompt Engineering: Detailed guidelines on model fine-tuning and prompt engineering for custom applications.
- Zilliz Cloud: Information on building vector-based search systems using Milvus, especially for large-scale data retrieval in enterprise environments.
- AWS SageMaker: Extensive documentation on building, training, and deploying ML models, including embedding generation and managed ML services.
- RAG Research by Facebook AI Research: Insights into the architecture and real-world effectiveness of Retrieval-Augmented Generation.
- Milvus Documentation: Guide on implementing and scaling vector search with Milvus, powering retrieval in RAG systems.
About ThamesTech AI
At ThamesTech AI, we specialize in building advanced AI solutions tailored to the specific needs of our clients across various industries, including healthcare, finance, customer support, and legal tech. With a team well-versed in cutting-edge AI architectures like Retrieval-Augmented Generation, we help organizations unlock the power of AI to deliver precise, context-rich responses, transforming data into actionable insights. Our commitment to excellence in cloud infrastructure and AI-driven innovation positions us as a trusted partner in the evolving landscape of enterprise AI.
For more information on how ThamesTech AI can support your organization in implementing RAG and other AI architectures, please reach out at info@thamestech.ai.