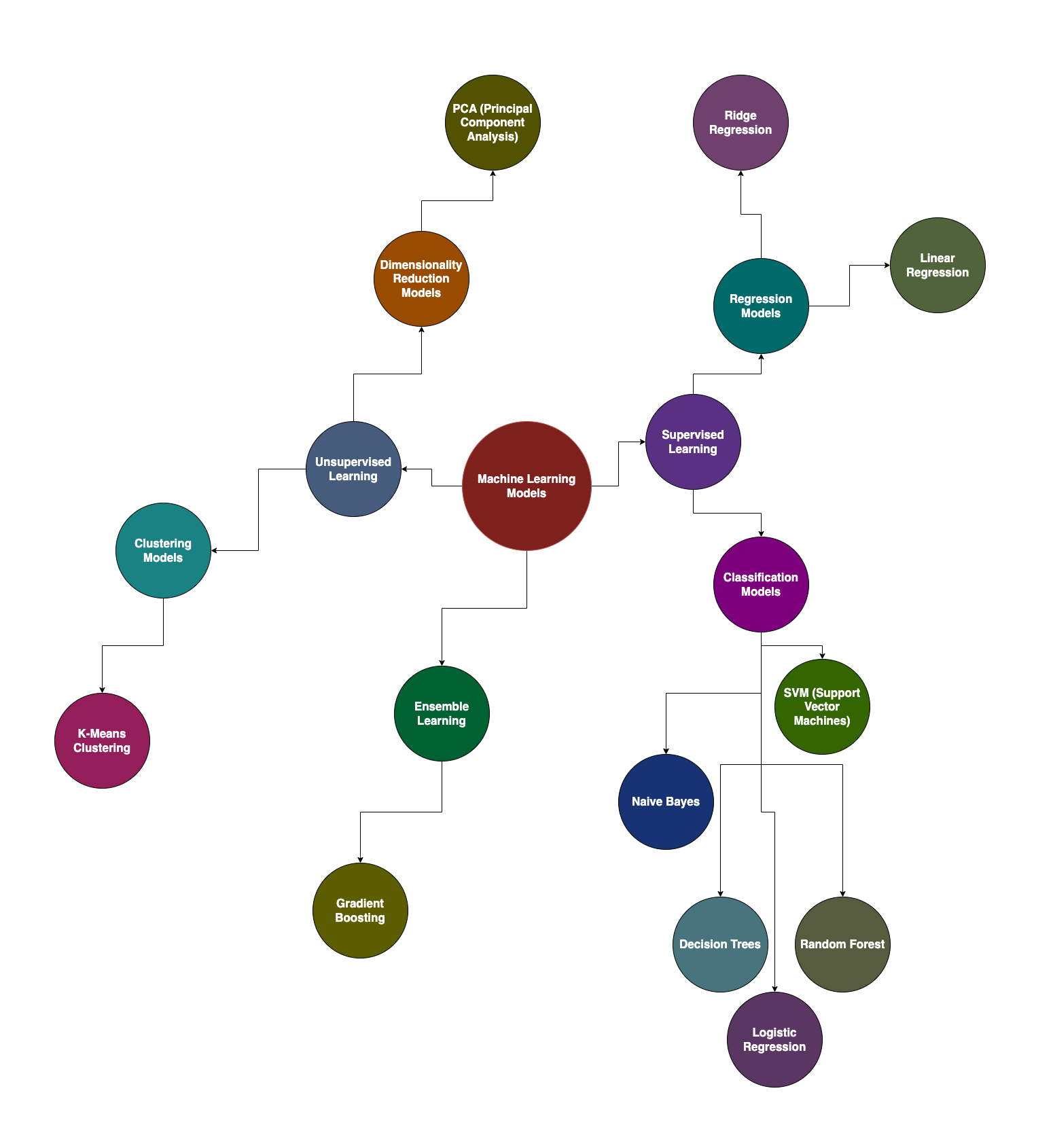
At ThamesTech AI, we’re passionate about leveraging cutting-edge technology to drive innovation and efficiency. Machine learning models for business are at the core of our AI-powered solutions, enabling businesses to make smarter decisions, automate processes, and uncover valuable insights from data.
In this blog, we’ll explore the most widely used machine learning models for business, breaking down their inner workings, discussing advanced concepts, and highlighting real-world use cases. Whether you’re looking to integrate AI into your business or expand your understanding of machine learning, this guide will equip you with a solid foundation.
1. Linear Regression: Predicting Continuous Business Outcomes
Overview:
Linear Regression is a fundamental model for predicting continuous outcomes, making it ideal for tasks such as sales forecasting, budget predictions, or cost estimations. It assumes a linear relationship between the features (input) and the outcome (target).
How It Works:
This model fits a straight line through the data, minimizing the difference between predicted and actual values:
y=b0+b1X1+b2X2+⋯+bnXn
Where y is the predicted value, and X1,X2,…,Xn are the input features.
Key Applications:
- Real Estate: Predicting property prices based on location, size, and amenities.
- Marketing: Estimating the impact of ad spend on revenue growth.
- Operations: Forecasting fuel or resource consumption based on historical trends.
Explore an in-depth guide on Linear Regression with Scikit-Learn.
ThamesTech AI Perspective:
At ThamesTech AI, we often implement Linear Regression models to provide our clients with predictive analytics that allow for accurate financial forecasting and operational efficiency improvements.
Python Example:
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0) # Ridge regularization to prevent overfitting
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
2. Logistic Regression: Classifying Business Outcomes
Overview:
Logistic Regression is ideal for binary classification tasks, such as determining whether a customer will churn, whether an email is spam, or whether a transaction is fraudulent. It’s widely used for decision-making where outputs are categorical.
How It Works:
The model uses a logistic function to map predicted values to probabilities, making it perfect for classifying inputs into two or more categories:
P(y=1∣X)=1/1+e−(b0+b1X1+⋯+bnXn)
Key Applications:
- Customer Retention: Predicting whether a customer is likely to churn based on behavioral patterns.
- Risk Management: Classifying loan applications as high or low risk.
- Marketing: Identifying the likelihood of a customer purchasing a product.
ThamesTech AI Perspective:
Logistic Regression is a go-to tool at ThamesTech AI for predictive maintenance and fraud detection systems. It enables businesses to make swift and reliable decisions based on past trends.
Python Example:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l1', solver='saga', C=1.0) # L1 regularization
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
3. Decision Trees: Simplifying Complex Business Decisions
Overview:
Decision Trees are intuitive models that simulate decision-making processes by splitting data into branches based on specific features. Each branch leads to an outcome, making this model great for tasks like loan approval or customer segmentation.
How It Works:
The tree splits the dataset at each node, choosing the feature that maximizes information gain. The process continues until it reaches the leaf nodes, which represent the final prediction.
Key Applications:
- Loan Approval: Automating the decision-making process for approving or rejecting loans.
- Healthcare: Diagnosing diseases by evaluating patient symptoms and test results.
- Human Resources: Predicting employee turnover based on performance metrics.
ThamesTech AI Perspective:
We use decision trees at ThamesTech AI to build clear and interpretable decision models for our clients, especially in domains like financial services and healthcare, where transparency is critical.
Python Example:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=5, min_samples_split=10)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
4. Random Forest: Robust, Accurate Predictions
Overview:
Random Forest improves decision trees by creating an ensemble of multiple trees, reducing overfitting and enhancing accuracy. It’s highly effective for both classification and regression tasks.
How It Works:
Each tree is built on a random subset of the data and features, and the model aggregates their results to make the final prediction. This ensemble approach ensures more reliable outcomes.
Key Applications:
- Fraud Detection: Identifying fraudulent transactions in real time.
- Customer Satisfaction: Predicting customer satisfaction based on feedback and behavior.
- Supply Chain: Forecasting demand and optimizing inventory levels.
ThamesTech AI Perspective:
At ThamesTech AI, we leverage Random Forests for complex business problems requiring high accuracy, such as fraud detection systems and predictive maintenance solutions.
Python Example:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, max_depth=10, max_features='sqrt')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
5. K-Nearest Neighbors (KNN): Finding Similarities in Data
Overview:
K-Nearest Neighbors (KNN) is a simple, non-parametric algorithm that classifies data points based on their proximity to other labeled points. It’s particularly useful for tasks like image recognition, recommendation systems, and customer segmentation.
How It Works:
KNN doesn’t build an explicit model. Instead, it compares a query point to its k nearest neighbors and assigns the most common class.
Key Applications:
- Recommendation Systems: Suggesting products based on similar customer preferences.
- Handwriting Recognition: Identifying handwritten digits or characters.
- Customer Segmentation: Grouping customers based on behavior and preferences.
ThamesTech AI Perspective:
At ThamesTech AI, we utilize KNN for personalized recommendation engines, helping businesses provide tailored experiences to their customers.
Python Example:
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=5, metric='euclidean')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
6. Support Vector Machines (SVM): Optimal Boundary Classification
Overview:
Support Vector Machines (SVM) are powerful classifiers that aim to find the optimal boundary between classes. SVM excels at handling high-dimensional data and is particularly effective in image classification and text categorization.
How It Works:
SVM constructs a hyperplane that separates data points from different classes, maximizing the margin between them. If the data isn’t linearly separable, SVM uses a kernel trick to project data into higher dimensions.
Key Applications:
- Text Categorization: Sorting documents into categories, such as news articles or emails.
- Image Classification: Identifying objects in images or videos.
- Medical Diagnosis: Detecting patterns in medical imaging to classify diseases.
ThamesTech AI Perspective:
SVM is one of the key models we implement for high-stakes applications such as medical image classification and fraud detection, where precision is critical.
Python Example:
from sklearn.svm import SVC
model = SVC(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
7. Naive Bayes: Fast and Effective Classification for Text Data
Overview:
Naive Bayes is a probabilistic classifier that works exceptionally well for text classification tasks like spam detection and sentiment analysis. Despite its simplicity, it’s often highly effective, particularly when combined with natural language processing (NLP) techniques.
How It Works:
Naive Bayes applies Bayes’ Theorem to calculate the probability of a class given the input features. It assumes that features are independent of each other (hence the “naive” assumption).
Key Applications:
- Spam Detection: Classifying emails as spam or not based on their content.
- Sentiment Analysis: Analyzing customer reviews to determine if they are positive or negative.
- Document Classification: Categorizing documents based on their content.
ThamesTech AI Perspective:
We use Naive Bayes in combination with natural language processing at ThamesTech AI to build robust spam detection and sentiment analysis systems for e-commerce and service-based businesses.
Python Example:
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
8. K-Means Clustering: Segmenting Data for Deeper Insights
Overview:
K-Means is an unsupervised learning algorithm that groups data into clusters based on their similarity. It’s commonly used in customer segmentation, market analysis, and even image compression.
How It Works:
The algorithm assigns data points to K clusters by minimizing the variance within each cluster. Centroids are recalculated until convergence.
Key Applications:
- Customer Segmentation: Grouping customers by behavior or preferences to optimize marketing strategies.
- Market Basket Analysis: Identifying product clusters that tend to be purchased together.
- Image Compression: Reducing the number of colors in an image while maintaining quality.
Dive into K-Means Clustering with Scikit-Learn.
ThamesTech AI Perspective:
We leverage K-Means at ThamesTech AI to help businesses better understand their customer base and identify valuable segments for targeted marketing and product recommendations.
Python Example:
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3, init='k-means++')
model.fit(X)
clusters = model.predict(X)
9. Principal Component Analysis (PCA): Reducing Complexity in High-Dimensional Data
Overview:
Principal Component Analysis (PCA) is a dimensionality reduction technique that transforms high-dimensional datasets into fewer dimensions without losing much information. It’s commonly used in data preprocessing to simplify datasets before applying other machine learning models.
How It Works:
PCA identifies the principal components (directions of maximum variance) in the data and projects it onto these new axes, capturing the most important information while reducing the number of features.
Key Applications:
- Data Visualization: Simplifying high-dimensional data for easier visualization.
- Preprocessing: Reducing the complexity of data before applying other models like SVM or KNN.
- Noise Reduction: Filtering out noise from datasets while retaining critical information.
Learn more about PCA with Scikit-Learn.
ThamesTech AI Perspective:
At ThamesTech AI, we often use PCA as part of the data preprocessing pipeline to simplify large, complex datasets and make them more manageable for machine learning models.
Python Example:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(X)
10. Gradient Boosting: Building Strong Models from Weak Learners
Overview:
Gradient Boosting is an advanced ensemble technique that builds strong predictive models by combining multiple weak learners, typically decision trees. It’s widely used for tasks like sales forecasting, fraud detection, and churn prediction.
How It Works:
Gradient Boosting builds trees sequentially, where each new tree corrects the residual errors of the previous one. This iterative approach makes it highly effective for structured data.
Key Applications:
- Sales Forecasting: Predicting future sales based on historical trends.
- Fraud Detection: Identifying anomalies in financial transactions.
- Customer Churn: Predicting which customers are at risk of leaving.
ThamesTech AI Perspective:
At ThamesTech AI, we use Gradient Boosting for complex business problems that require high accuracy and reliability, such as predictive analytics and fraud detection systems.
Python Example:
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=200, learning_rate=0.1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
Conclusion: Driving Business Success with Machine Learning
At ThamesTech AI, we specialize in providing businesses with the power of machine learning to unlock actionable insights, automate decision-making, and drive efficiency. From predictive analytics to advanced classification tasks, we help businesses across industries harness the potential of AI-driven solutions.
Whether you’re new to machine learning or looking to deepen your technical understanding, these models form the foundation of many AI systems that are transforming industries. As always, experimentation, iteration, and continuous learning are key to mastering these technologies.
If you’re interested in implementing machine learning solutions tailored to your business, contact ThamesTech AI today to learn more about our consulting services and AI-powered solutions!